ISUCON13に参加して最終スコア37,416で10X賞をいただきました
今年も @nari_ex、@kur_neko、@shiimaxx の3人で「( (0) / (0)) ☆祝☆」というチームで参加しました。
最終スコアは37,416で46位。目標のTOP30には届きませんでしたが10X賞をいただくことができました。ありがとうございます!
やったこと
インデックス追加
go-mysql-query-digestでスロークエリログを集計して、集計結果の上位のクエリでインデックスを追加して改善できそうなものがあったときに都度追加していました。最終的に追加したものは次のとおり。PowerDNSをMySQL バックエンドで最後まで使い続けたのでisudnsにもインデックスを追加しています。
isupipe
ALTER TABLE reactions ADD INDEX livestream_id_idx (livestream_id); ALTER TABLE livecomments ADD INDEX livestream_id_idx (livestream_id); ALTER TABLE livestream_tags ADD INDEX livestream_id_idx (livestream_id); ALTER TABLE icons ADD INDEX user_id_idx (user_id); ALTER TABLE themes ADD INDEX user_id_idx (user_id); ALTER TABLE ng_words ADD INDEX user_id_livestream_id_idx (user_id, livestream_id); ALTER TABLE reservation_slots ADD INDEX start_at_end_at_idx (start_at, end_at);
isudns
ALTER TABLE records ADD INDEX disabled_name_domain_id_idx (disabled, name, domain_id); ALTER TABLE records ADD INDEX disabled_type_name_idx (disabled, type, name);
getUserStatisticsHandlerとgetLivestreamStatisticsHandlerのN+1クエリ解消
getUserStatisticsHandler内のランク算出の処理でユーザ毎にリアクション数とチップ合計を取得するN+1クエリがあったので、それぞれGROUP BYで集計して取得するように変更しました。同じようなN+1クエリがgetLivestreamStatisticsHandlerがあったのでそちらも同じように修正しました。
DNS水責め攻撃対策
iptablesで存在しないドメインの名前解決のパケットをDROPするというアプローチを取りました。方針検討と実装の大半はnari_exにやってもらいました。
初期化処理で以下のスクリプトを実行してiptablesにルールを追加します。
#!/bin/bash # 冪等性を保つために既存のルールをflush sudo iptables -F INPUT # 登録済みのサブドメインを許可 mysql isudns -uisucon -pisucon -e 'select name from records' -s | sed 's/u.isucon.dev//' | tr -d . | grep -v '^$' | xargs -I%% sudo iptables -A INPUT -p udp --dport 53 -m string --string %% --algo bm -j ACCEPT # ".u.isucon.dev"を含むDNSリクエストをDROP(水攻め対策) sudo iptables -A INPUT -p udp --dport 53 -m string --hex-string "|017506697375636f6e0364657600|" --algo bm --from 41 --to 512 -j DROP # u.isucon.devを許可(INPUTチェインはpolicy ACCEPTなのでこのルールは不要) # sudo iptables -A INPUT -p udp --dport 53 -m string --hex-string "|7506697375636f6e0364657600|" --algo bm --from 41 --to 512 -j ACCEPT
POST /api/registerでサブドメインを追加するタイミングでそのサブドメインの名前解決を許可するルールを追加します。
if out, err := exec.Command("sudo", "iptables", "-I", "INPUT", "-p", "udp", "--dport", "53", "-m", "string", "--string", req.Name, "--algo", "bm", "-j", "ACCEPT").CombinedOutput(); err != nil { return echo.NewHTTPError(http.StatusInternalServerError, string(out)+": "+err.Error()) }
iptablesのルール追加をするPOST /api/registerはPowerDNSが動いているサーバで捌く必要があるので、Nginxで/api/registerの振り分けを固定します。
location /api/register {
proxy_set_header Host $host;
proxy_pass http://<PowerDNSが動いているサーバ>:8080;
}
GET /api/user/:username/iconで304を返す
アプリで実装するのが手軽そうだったので次のように実装しました。
iconsテーブルにsha256というカラムを追加したうえでPOST /api/iconでimageを保存するときにSHA256値を計算して保存しておきます。
imageHash := sha256.Sum256(req.Image)
rs, err := tx.ExecContext(ctx, "INSERT INTO icons (user_id, image, sha256) VALUES (?, ?, ?)", userID, req.Image, fmt.Sprintf("%x", imageHash))
if err != nil {
return echo.NewHTTPError(http.StatusInternalServerError, "failed to insert new user icon: "+err.Error())
}
GET /api/user/:username/iconにIf-None-Matchヘッダが含まれていてかつデータベース内のSHA256値と同一の場合は304レスポンスを返します。ヘッダ側に"が含まれていて同一と判定されない問題がありましたがベンチマーク実行時にちゃんと304を返しているかを確認していたので早めに気づけて修正できました。
ifNoneMatch := c.Request().Header.Get("If-None-Match") ... if ifNoneMatch != "" { var hash string if err := tx.GetContext(ctx, &hash, "SELECT sha256 FROM icons WHERE user_id = ?", user.ID); err != nil { if errors.Is(err, sql.ErrNoRows) { return c.File(fallbackImage) } else { return echo.NewHTTPError(http.StatusInternalServerError, "failed to get user icon hash: "+err.Error()) } } if hash == strings.Trim(ifNoneMatch, `"`) { return c.NoContent(http.StatusNotModified) } }
fillLivestreamResponseのN+1解消
IN句でまとめて取得するように修正しました。
inQuery, inArgs, err := sqlx.In("SELECT * FROM tags WHERE id IN (?)", tagIDs) if err != nil { return Livestream{}, err } var tagModels []TagModel if err := tx.SelectContext(ctx, &tagModels, inQuery, inArgs...); err != nil { return Livestream{}, err }
サーバ構成変更
最終構成はこれでした。1台目はNginxとPowerDNSのCPU使用率がそこそこ高かったのでAppの振り分けは3台目の比重を多めにしました。
『達人が教えるWebパフォーマンスチューニング』を読んだ
レビューに参加した『達人が教えるWebパフォーマンスチューニング』をご恵贈いただきました。ありがとうございます!

感想
本書では、Webサービスを高速化するための基礎知識や考え方、そして具体的な計測と改善の手法についてISUCONを題材にして解説しています。
本書をひと通り読むことで、Webパフォーマンスチューニングにおいて最も遅い箇所(ボトルネック)を特定して改善することが重要であること、最も遅い箇所(ボトルネック)を特定する方法、Webサーバ・アプリケーション・データベース・OSといった各レイヤにおける高速化の手法を学ぶことができます。
学んだ知識をISUCONの環境を使って実際に手を動かして試せるというのは重要なポイントだと思います。
私自身、WebパフォーマンスチューニングのいろはをISUCONで学んできました。ISUCONで学んだ計測や高速化の手法は、業務において目の前で発生しているWebサービスのパフォーマンス問題に立ち向かう際に大いに役立ちました。
本書で学んだ知識をISUCONの各種環境で実践して理解を深めることで、実際の業務に適用できるノウハウが獲得できるんじゃないかと思います。
付録Bのベンチマーカの実装はISUCON勢として興味深く読ませていただきました。なかでも実装パターンの解説については、ISUCONのベンチマーカを実装したい人だけでなくGoを書く人にとっても参考になると思います。
株式会社Topotalに入社して半年経ちました
2021/12/01に株式会社Topotalに入社していました。
本日12/1 株式会社 Topotal に入社しました。
— Takatada Yoshima (@shiimaxx) 2021年12月1日
SRE as a Service を提供するエンジニアとして、お客様の SRE の実践をお手伝いしていきます!https://t.co/ITfMDu0eSN
自分はフルタイムでSRE as a ServiceというSite Reliability Engineering(以降SRE)を軸にした技術支援サービスの提供をしています。
入社半年という区切りのよい時期なので、半年間で取り組んだことをまとめてみました。
自身の振り返りが主ですが、現時点でTopotalのSRE as a Serviceの業務内容について外に出ている情報はそう多くないので、ご興味を持っていただいた方向けの参考情報として役立てばと思っています。
やったこと
前提として2〜3社のお客様の支援を同時並行で行っています。他にも細々したものはありますが主にこんな感じです。
- Terraform AWS Providerのアップデート
- DatadogでgRPCエンドポイントのモニタリング
- コンテナレジストリ間でイメージ同期する仕組み作り
- GKEクラスタの可用性向上
- モニタリングの整備
- Infrastructure as codeの導入
- SLO導入
お客様によってインフラ/SRE組織のフェーズは様々なので、お手伝いする内容も幅広くなっています。
お客様のインフラ/SRE組織が持っている明確な課題に取り組むこともあれば(1,2,3)、何となく不安に感じている箇所を掘り下げて課題整理からやらせてもらうこともあります(4,5)。
また、SREを実践するための取り組みの支援もしました(6,7)。この場合、単にツールやプラクティスを導入するだけではなく、組織にあわせてどのように運用できるかを一緒に考えたり、お客様の社内でのSREの理解促進のために各種取り組みのモチベーションを説明するドキュメントを書くということもしました。
SREの実践の支援においては、自分自身がSRE自体に対する一定の理解はあるものの、実際に組織に導入するということはやったことがなかったため、社内のメンバーから知見をもらったり、日々SRE book、SRE Workbook、Seeking SRE、各種事例やドキュメントなどを参照して理解を深めつつ、お客様の組織における実践に適用していくということをやっていました。
技術トピックとしては、AWS全般、GCP(GKE、Cloud Run)、Terraformあたりを触ることが多かったです。
コードを書く機会もたくさんありました。ちょっとしたツールを書いたり、運用にがっつり絡むソフトウェアを書いたり、一部OSSとして公開しているものもあります。
ちなみに今のところプログラミング言語の指定があったことはなく、その時々で用途や好みで選定していました。自分の場合はGo、Ruby、Pythonのどれかにしていました。
Topotalでは、ソフトウェアで運用の課題を解決することが推奨されているので、今後もどんどんやっていきたいと思っています。
宣伝
TopotalではSREを積極採用しています。ご興味のある方は問い合わせ・申込みをしていただけると嬉しいです!
ISUCON11で予選敗退して悔しかったので予選突破ラインのスコアが出るまで延長戦をやりました
去年に引き続き、今年も @nari_ex、@kur_neko、@shiimaxx の3人で「( (0) / (0)) ☆祝☆」というチームで参加しました。結果は予選敗退、当日のベストスコアは35902でした。
当日やったこと
利用言語はGoです。
- 予選当日マニュアル、アプリケーションマニュアルをしっかり読む
- ボトルネック調査
- アクセスログ解析: kataribe
- スロークエリログ解析: pt-query-digest
- システムリソース: top, dstat
- アプリケーション: pprof, fgprof
- インデックス追加
ALTER TABLE isu_condition ADD INDEX idx_jia_isu_uuid_timestamp (jia_isu_uuid, timestamp);
- 自動prepared statementを抑制するためにDSNに
interpolateParams=trueを追加 - トランザクション内でやる必要のない処理を外出し
GET /api/trend- ISUの性格は固定だったのでアプリケーション内部でsliceとして持たせてDB参照しない
- 不要なカラムは取得しない
- アプリケーション内で0.8秒キャッシュ
- MariaDBをMySQL 8.0に変更
- サーバ構成変更
この他にDBに入っている画像の外出しやGET /api/trendのN+1対策をしていましたが、どちらも実装しきれず諦めています。
延長戦
後日実施した反省会で、スコアを上げるための要点が正確に把握できておらず注力する箇所を間違っていた、そもそも実装スピードが足りない、という課題があがりました。
これらは自然に身につくようなものでもなく継続的に練習が必要だという話になったので、ひとまずはISUCON11の予選問題を予選突破ラインのスコアが出るまでやることにしました。
解法を知らない状態でやりたかったので、予選関連エントリはほぼ読まず(1〜2エントリだけ軽く目を通した)、予選講評は読まない状態でやりました。
環境
MacBook Pro (13-inch, 2017) 上にVagrantで以下の環境を起動しました。
- matsuu/vagrant-isucon/isucon11-qualifier-standalone
- CPU 2コア、メモリ 2GB
- ベンチマーカ相乗り
スコア
予選突破ラインのスコアは、チーム「俺達の戦いはこれまでだ」の106094なので、このスコア以上を目標にします。本番はAmazon EC2のインスタンスを3台利用できるので構成の差異がありますが、縛りプレイということにして上記の環境で予選突破ラインのスコアを目指すことにしました。
初期スコアは1242。当日やったこと(構成変更以外)を適用した後のスコアは18019でした。
〜 35000
POST /api/condition/<uuid> のINSERTをbulk insertにする → 20534
予選関連エントリでチラ見してしまった内容なのですが、リクエストに含まれるISUのコンディションを都度INSERTしている箇所をbulk insertに変更しました。
sqlxのNamedExecを利用して以下のように実装。
var values []map[string]interface{} for _, cond := range req { timestamp := time.Unix(cond.Timestamp, 0) if !isValidConditionFormat(cond.Condition) { return c.String(http.StatusBadRequest, "bad request body") } values = append(values, map[string]interface{}{ "jia_isu_uuid": jiaIsuUUID, "timestamp": timestamp, "is_sitting": cond.IsSitting, "condition": cond.Condition, "message": cond.Message, }) } _, err = tx.NamedExec( "INSERT INTO `isu_condition`"+ " (`jia_isu_uuid`, `timestamp`, `is_sitting`, `condition`, `message`)"+ " VALUES (:jia_isu_uuid, :timestamp, :is_sitting, :condition, :message)", values, ) if err != nil { c.Logger().Errorf("db error: %v", err) return c.NoContent(http.StatusInternalServerError) }
iconをDBから外出し → 21813
当日に@kur_nekoが8割方実装してくれていたのを再利用して実装しました。
最新のISUのコンディションをキャッシュしてGET /api/getTrend、GET /api/isuのDB参照を減らす → 23686
initializeで以下の処理を実行してキャッシュを準備、POST /api/condition/:jia_isu_uuidでコンディションを受けっ取ったときにも都度最新データを更新するようにして、最新のISUのコンディションを参照する箇所ではこのキャッシュを利用するようにしました。
var latestIsuConditions sync.Map func prepareLatestIsuCondition() error { rowsx, err := db.Queryx("SELECT `isu_condition`.* FROM (SELECT `jia_isu_uuid`, MAX(`timestamp`) `latest_timestamp` FROM `isu_condition` GROUP BY `jia_isu_uuid`) `tmp`, `isu_condition` WHERE `tmp`.`jia_isu_uuid` = `isu_condition`.`jia_isu_uuid` AND `tmp`.`latest_timestamp` = `isu_condition`.`timestamp`") if err != nil { return err } for rowsx.Next() { var condition IsuCondition err = rowsx.StructScan(&condition) if err != nil { return err } latestIsuConditions.Store(condition.JIAIsuUUID, condition) } return nil }
GET /api/condition/:jia_isu_uuid の改善 →27362
isu_conditionテーブルにis_dirty、is_overweight、is_brokenカラムを追加して必要なコンディションのレコードのみ取得できるようにしたり、必要な件数分のレコードのみを取得するようにLIMITを追加したりしました。
dropProbability := 0.8、コネクションプールの接続数を100 →34398
試しにやってみたらスコアが結構上がりました。これまでの変更が効いたプチブレイクスルーと思われます。
〜85000
GET /api/isu/:jia_isu_uuid/graph の改善 → 41850
isu_conditionテーブルから指定されたjia_isu_uuidの全レコードを引っ張っていたが、コードを読んでみると1日分のデータしか利用していないようだったので、timestampカラムで条件を絞ってDBからのデータ取得の件数を絞りました。
あと、calculateGraphDataPointの処理はWINDOW関数というやつでできるのでは、と思い頑張ってSQLを作って実装。が、この時点ではスコアにはあまり効果がありませんでした。インデックスを上手く使わせられず、EXPLAINして実行計画を見てみるとUsing temporary; Using filesortが出ていたので単にアプリケーションの負荷がMySQLに移っただけで全体としての効果が薄かったのかもしれません。
query := "SELECT\n" + " `isu_condition`.*,\n" + " DATE_FORMAT(`timestamp`, '%Y-%m-%d %H:00:00') `truncate_timestamp`,\n" + " SUM((\n" + " CASE WHEN `condition_level` >= 3 THEN 1\n" + " WHEN `condition_level` >= 1 THEN 2\n" + " ELSE 3 END\n" + " )) OVER w * 100 / 3 / COUNT(*) OVER w `score`,\n" + " AVG(`is_sitting`) OVER w * 100 `sitting_percentage`,\n" + " AVG(`is_broken`) OVER w * 100 `is_broken_percentage`,\n" + " AVG(`is_overweight`) OVER w * 100 `is_overweight_percentage`,\n" + " AVG(`is_dirty`) OVER w * 100 `is_dirty_percentage`\n" + " FROM `isu_condition`\n" + " WHERE `jia_isu_uuid` = ?\n" + " AND `timestamp` >= ? AND `timestamp` < ?\n" + " WINDOW w AS (PARTITION BY `truncate_timestamp`)\n" + " ORDER BY `timestamp` ASC"
いくつかトランザクションを削除 → 49274
pt-query-digestのスロークエリログ解析の結果から、ロック待ちで時間がかかっているクエリが多かったので改めて見直したところ、必要のないトランザクションがいくつかあったので削除しました。
トランザクションについてはこの後も何度か見直していて、異常系を考慮しなければなくてもよいものと読み取れたので最終的には全廃しました。
dropProbability := 0.7 → 51876
細かい変更を色々→ 84391
JIAServiceURLはDBではなくグローバル変数に保存するisu_conditionからAUTO_INCREMENTなidカラムを削除してプライマリキーをjia_isu_uuidとtimestampの複合キーに変更- loglevelを
DEBUGからERRORに変更 dropProbability := 0.6- 作成済みのISUのリストをキャッシュして、以下のようなISUの存在チェックのためのクエリを削減
var count int err = db.Get(&count, "SELECT COUNT(*) FROM `isu` WHERE `jia_isu_uuid` = ?", jiaIsuUUID)
〜10000over
POST /api/condition/:jia_isu_uuid で受け取ったコンディションをキューイングして単一のGoroutineでbulk insert → 96413
このあたりで若干手詰まり感。
スコアを上げるにはPOST /api/condition/:jia_isu_uuidのスループットを上げる必要があるんだろうな、とは考えていたものの手段が思いつかず。そこで、改めて予選当日マニュアルを読んでみたところ、
POST /api/condition/:jia_isu_uuid で受け取ったコンディションの反映が遅れることをベンチマーカーは許容しています。
という記載が目につき、POST /api/condition/:jia_isu_uuidのレスポンスを返す時点でコンディションが反映されていなくてよいのであれば、一旦キューイングして一定間隔でまとめてINSERTするようにすれば競合せずにスループットが上がるのでは、と考えて実装してみました。
POST /api/condition/:jia_isu_uuidの中からは送られてきたコンディションをchannelで送信するだけにして、実際にDBにINSERTする処理はgoroutineで動かしている以下の関数内でやります。
func updateIsuCondition(q chan map[string]interface{}) { var records []map[string]interface{} for { wait: for { select { case record := <-q: records = append(records, record) case <-time.After(10 * time.Millisecond): break wait } } if len(records) > 0 { _, err := db.NamedExec( "INSERT INTO `isu_condition`"+ " (`jia_isu_uuid`, `timestamp`, `is_sitting`, `condition`, `message`, `is_dirty`, `is_overweight`, `is_broken`)"+ " VALUES (:jia_isu_uuid, :timestamp, :is_sitting, :condition, :message, :is_dirty, :is_overweight, :is_broken)", records, ) if err != nil { fmt.Println(err) } records = []map[string]interface{}{} } } }
これが効いて一気にスコアが10k以上アップ。システムリソースに余裕がある状態だったので、更にdropProbabilityを調整していきます。
dropProbability := 0.4 → 116797
dropProbabilityを0.5→0.4→0.3と調整してみたところ、0.4で最高スコアが出ました。目標であった106094を超えるスコアも達成。
03:54:51.191862 score: 116797(116828 - 31) : pass 03:54:51.191882 deduction: 31 / timeout: 0 03:54:51.191889 <=== sendResult finish
まとめ
予選の翌日から2週間、少しず進めてある程度のスコアを出すことができました。実装の練習になりますし、どのようにスコアが積み上がっていくのかというのを体験できてよかったと思います。
このブログを大方書いたあとにISUCON11 予選問題の解説と講評を読んでみました。実施した内容が想定解法から大きくハズレていないという点についてはよかったのですが、そこに辿り着くまでに結構遠回りをしてしまっていたので、引き続き計測結果から正確にボトルネックを読み取れるようになるという課題に向き合う必要があるかなと思っています。ISUCONでは8時間で成果を出す必要がありますし。
最後に、運営の皆様今年もISUCONを開催していただきありがとうございます! 予選本番だけでなく、事前練習や延長戦も含めて長く楽しませていただいています。本選問題が公開されたらそちらにもチャレンジしてみようと思います。
ISUCON10予選に参加しました
ISUCON10の予選にnari_exさん、kur_nekoさんと「( (0) / (0)) ☆祝☆」というチームで参加しました。最終スコアは1422でした。
ISUCON7から同じメンバーで参加しているのですが、今年も予選突破できず悔しい。
事前準備
個人練習でISUCON8、ISUCON9の予選問題をGoで解きました。いずれも予選突破ラインのスコアが出るまでチューニングし、その過程で以下のことの練習や確認ができたと思います。
- レギュレーション、マニュアル、アプリケーション仕様書から問題のポイントをつかむ
- Goでのオンメモリキャッシュや並行処理の書き方
- sqlxやgo-redisなどのライブラリの利用方法
- kataribeやpprofなどの解析ツールの利用方法と解析結果の見方
- MySQLのロックの挙動について
また、予選の前々日にZoomで打ち合わせをしました。昨年の反省を振り返りつつ、レギュレーションの読み合わせや役割分担を行いました。
当日
それぞれ自宅からリモートで参加しました。Zoomを常時接続しておいて、テキストでの情報共有はSlack、Scrapboxを使いわけて行いました。
序盤
昨年の反省から、まずはサービスの背景やアプリケーションについてしっかり理解してから手を動かそうと話していたので、nari_exさんとわたしでマニュアルを読む、サービスを使ってみる、ということをやって、それぞれScrapboxに情報をまとめていきました。
そのあいだにkur_nekoさんには、サーバの初期セットアップやミドルウェア解析用のログ出力設定などの下回りの整備をやってもらいました。
初回ベンチマークを実行して初期スコアは500ちょっと。
ベンチマーク実行中にtopコマンドの出力を眺めていたらMySQLのCPU使用率が支配的だったので、まずはインデックス追加やクエリの改善・削減をやっていく方針になりました。
今回スコアに直結するエンドポイントは、POST /api/chair/buy/:idとPOST /api/estate/req_doc/:id で、そこへの導線になるであろう検索が重要そう、というのがマニュアルを読んだうえでの理解。kataribeでアクセスログ解析を行った結果を見ても検索まわりのURLのリクエスト回数やレスポンスタイムが多かったので、そのあたりを中心に見ていきました。やったことは次のとおり。
- インデックス追加
GET /api/recommended_estate/:idのクエリの修正- イスがドアに入るかどうかはイスの短辺だけでチェックすればOK
- MySQL 8.0化
ORDER BY popularity DESCの部分で降順インデックスを使うために採用- スコアが下がってしまったのでパラメータチューニングを実施
- アップデート前よりスコアは下がってしまったが今後の伸びしろに期待してとりあえずそのまま利用継続
中盤
検索APIのクエリでrent、doorHeight、doorWidthなどの条件が範囲検索になっていてインデックスうまく使えていなかったので、それぞれ値に対応したrangeIdを保存するカラムを追加してそれを利用するように変更。
このあたりから/initializeの初期化処理が30秒以内に完了せずベンチマーク実行がFailするようになりました。
インデックス追加、カラム追加とそれに伴う初期データ更新をすべて初期化処理で行っていたので、インデックスやカラム追加後の初期データセットを別テーブル(estate_customize、chair_customize)にもっておいて、初期化処理を
CREATE TABLE estate LIKE estate_customize; INSERT INTO estate SELECT * FROM estate_customize;
でデータをコピーする方式に変更。作業に手間取って1時間くらい消費してしまったのがもったいなかった。
あとはBotからのアクセスが目立ってきたので、NginxでBotからのアクセスに503を返すようにしました。
終盤
この時点での最高スコアは1200ちょっと。予選突破ラインは2000くらいかなと予想していたのですが、残り時間も少なかったので大幅な改修には着手できず。
MySQL5.7→MySQL 8.0でスコアが下がってしまった分をバージョン差し戻しで取り戻せないかな、ということで差し戻してみたのですが効果がなかったのでやめ。
スロークエリログでSELECT COUNT(*)のクエリが相対して多くなっていたので、必要なインデックスをひたすら追加するなどして、最終スコア1422でFinishしました。
まとめ
予選突破ラインのスコアを出すためには施策をもう3、4手打つ必要があったと思っていて、それができなかったのは実力不足だったと思っています。 予選問題のゲーム性の理解やチームの役割分担は例年よりうまく行った感があったので、さらに上積みしつつ来年もチャレンジしたいです。
運営の皆様、今年も楽しい問題をありがとうございました。予選突破された皆さんは本選でも頑張ってください。
GitLabのMergeRequestからChangelogを生成するglchとGitLab Releaseを作成するglr
GitHubにホストしているプロジェクトでは、Changelog生成にghchを、Releaseの作成にはghrを利用しているのですが、同じようなことをGitLabにホストしているプロジェクトでもやりたかったので作りました。どちらもGo実装です。
glch
https://github.com/shiimaxx/glch
GitのタグとGitLabのMerge RequestからChangelogを生成します。ghchがGItのタグとGitHubのPull RequestからChangelogを生成するのでその挙動を参考にしました。
$ glch ## v0.2.0 - 2020-05-09 - Feature 2 shiimaxx/glch-demo!2 from [@shiimaxx](https://gitlab.com/shiimaxx) - Feature 1 shiimaxx/glch-demo!1 from [@shiimaxx](https://gitlab.com/shiimaxx) ## v0.1.0 - 2020-05-09 - Initial release
最新のタグ以降に更新がある場合は、デフォルトだとUnreleasedセクションに出力します。
$ glch ## Unreleased - 2020-05-09 - Feature 3 shiimaxx/glch-demo!3 from [@shiimaxx](https://gitlab.com/shiimaxx) ## v0.2.0 - 2020-05-09 - Feature 2 shiimaxx/glch-demo!2 from [@shiimaxx](https://gitlab.com/shiimaxx) - Feature 1 shiimaxx/glch-demo!1 from [@shiimaxx](https://gitlab.com/shiimaxx) ## v0.1.0 - 2020-05-09 - Initial release
-next-versionオプションを使うとUnreleasedの代わりにバージョンを指定できます。
$ glch -next-version v0.3.0 ## v0.3.0 - 2020-05-09 - Feature 3 shiimaxx/glch-demo!3 from [@shiimaxx](https://gitlab.com/shiimaxx) ## v0.2.0 - 2020-05-09 - Feature 2 shiimaxx/glch-demo!2 from [@shiimaxx](https://gitlab.com/shiimaxx) - Feature 1 shiimaxx/glch-demo!1 from [@shiimaxx](https://gitlab.com/shiimaxx) ## v0.1.0 - 2020-05-09 - Initial release
出力するChangelogのフォーマットは、keep a changelogを参考にしたものにしています。
glr
https://github.com/shiimaxx/glr
GitLabのReleaseを作成するCLIツールです。
-uploadオプションでファイルもしくはディレクトリを指定するとReleaseの作成とともにファイルをアップロードできます。
$ glr -upload ./dist v0.1.0 [Created release] Title: v0.1.0 Release assets: --> glr_v0.1.0_darwin_amd64.zip: https://gitlab.com/shiimaxx/glr-demo/uploads/.../glr_v0.1.0_darwin_amd64.zip --> glr_v0.1.0_linux_amd64.tar.gz: https://gitlab.com/shiimaxx/glr-demo/uploads/.../glr_v0.1.0_linux_amd64.tar.gz
アップロードしたファイルはRelease assetsになります。

ローカルのファイルをアップロードする方法とは別に、-asset-nameオプションと-asset-urlオプションを利用して任意の名前とURLでRelease assetsを作成する方法も用意しています。
これによりGitLab CI/CDのBuild artifactsやS3などに置いたファイルをRelease assetsにできます。
参考
Mackerelで負荷テスト中のリソースモニタリングを行う
Mackerel Advent Calendar 2019 22日目のエントリです。
Mackerelでは、ホストやミドルウェアのメトリックをグラフとして可視化することができます。日々のシステム状況の把握やキャパシティプランニング、トラブルシューティングの際に参照するのが主な用途だと思いますが、システムの運用を開始する前の負荷テストにおいても活用することができます。
本エントリでは、時系列データベースGraphiteの書き込みパフォーマンスの負荷テストを例にして、Mackerelによる負荷テスト中のメトリックの可視化とそれを活用してチューニングする過程を紹介します。
ひとつ注意点があります。Mackerelではメトリックを1分間隔で保持するので、負荷計測を短時間(数十秒〜数分)で行うケースではデータの解像度が足らずうまく利用することができません。
これから紹介するのは「ある想定したワークロードを継続的に問題なく処理できるか」を検証するために、数十分以上継続して負荷計測するケースです。
Graphite
はじめに計測対象のGraphiteについて説明します。
Graphiteは以下のコンポーネントで構成される時系列データベースです。
- Graphite-Web
- Carbon
- Whisper
各コンポーネントの連携については次の図が参考になります。
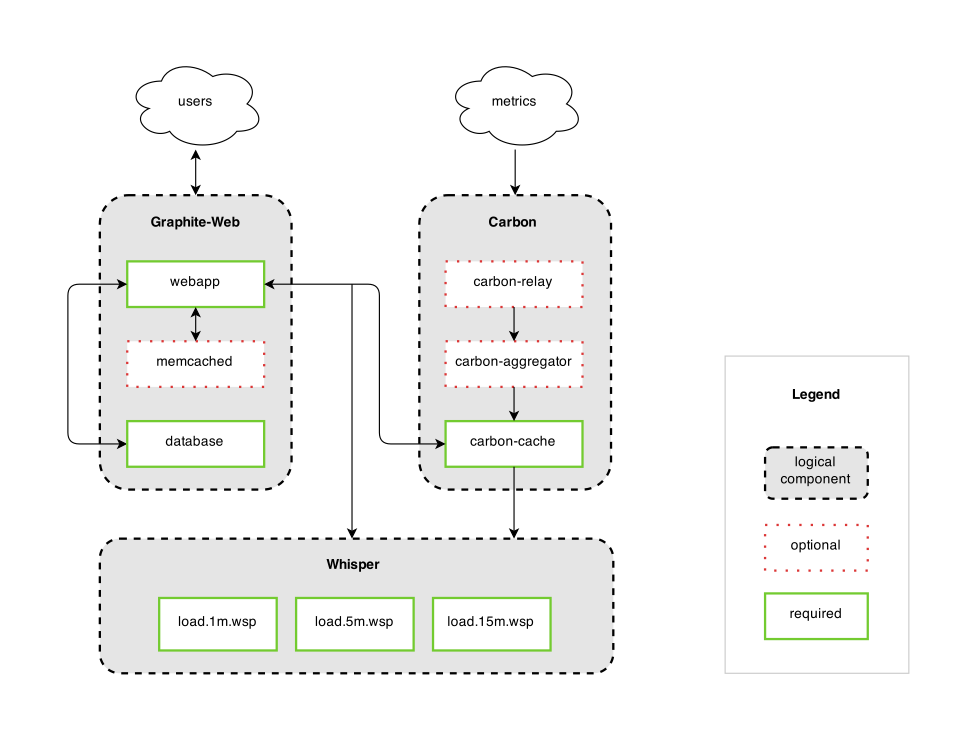
Graphiteにおいてメトリックを受信して書き込みを行うのはCarbonです。Carbonはデーモンとして稼働し、ネットワーク経由でメトリックを受信してそれをWhisper形式でファイルに書き込みます。
負荷テストではCarbonに対して大量のメトリックを送信することで負荷計測を行います。
検証環境
サーバ構成
- サーバ
- Microsoft Azure Standard F4s_v2(4 vcpus, 8 GiB memory)
- データディスク(Graphitデータ保存先)
- Premium SSD Managed Disks P30 (1024 GiB, 5000IOPS, 200 MB/second)
- OS
- Ubuntu Server 18.04 LST
Mackerelメトリックプラグイン
Graphiteのメトリック可視化のためにmackerel-plugin-graphiteを使います。
Graphiteは自身の統計情報を時系列データとして保持しています。mackerel-plugin-graphiteはこれをGraphite-Web経由で収集するプラグインです。
今回の負荷テストで主に確認するメトリックは次の2つです。
- Carbon Metrics Received
- 受信したメトリックのデータポイントの数
- Carbon Committed Points
- ディスクにフラッシュしたメトリックのデータポイントの数
受信したメトリックを遅延なくディスクにフラッシュできているかという、Graphiteの書き込みパフォーマンスに直結する値がここから読み取ることができるためです。
負荷テストツール
haggarというCarbonの負荷テストツールを使います。
haggarでは、並列数・メトリック数・メトリックの送信間隔などをオプションで指定してどの程度の負荷(メトリックの送信量)をかけるかを調整します。
以下は負荷調整に利用するオプションのデフォルトです。
$ haggar \
-agents=100 \
-flush-interval=10s \
-metrics=10000 \
-jitter=10s \
-metrics=10000 \
-spawn-interval=10s
デフォルトは次のような負荷のかけ方になります。
- 10秒(+最大10秒のゆらぎ)ごとに並列数を増やし(
-spawn-interval,-jitter) - 最大100並列で(
-agents) - それぞれ10000個のメトリックを(
-metrics=10000) - 10秒間隔でフラッシュする(
-flush-interval)
構築手順
負荷テスト開始時点までの構築手順を以下に載せています。
https://gist.github.com/shiimaxx/53b8dfe76b5f13bbff9f75777293e0f4
負荷計測
それではhaggarで負荷計測しつつ、Mackerelのグラフを見てみます。
haggarは次のように実行しました。最大並列数を300でそれぞれ2000個のメトリックをフラッシュします。その他はデフォルトです。
$ haggar -agents=300 -metrics=2000 -carbon=localhost:2003
負荷計測 - 1回目
負荷計測を1時間程度実行したあとのグラフです。




送信側の並列数が増えるにつれてCarbon Metrics Receivedが200万程度まで増えていっていますが、それと比較してCarbon Committed Pointsは1万くらいにしかなっていません。
メトリックの受信量に対してディスクへのフラッシュが追いついていないという状態です。
サーバリソースのグラフを見ると、CPUリソースは1コア分しか利用していません。また、データディスクは5000IOPSが上限のものを利用していますが、グラフでは10〜60IOPS程度です。
サーバリソースにまだ余裕があることから、サーバの性能不足によってGraphiteのデータ書き込みが追いついていないというわけではないことがわかります。 このようなケースでは、何かしらのエラーやミドルウェアの設定によってパフォーマンスが制限されている場合はあります。
Graphiteでは、MAX_UPDATES_PER_SECONDというパラメータでメトリック更新のためのディスク書き込みのレートを設定することができます。デフォルト値は500です。
この設定によってCarbonがメトリックをディスクに書き込む動作が制限されていた可能性があるので、設定を変更します。
設定値をinfにすると書き込みレートの制限がされません。また、メトリックの新規作成時の書き込みレートも同じように制限しないようにします。
/etc/carbon/carbon.conf
[cache] ... MAX_UPDATES_PER_SECOND = inf MAX_CREATES_PER_MINUTE = inf
負荷計測 - 2回目
設定変更後に再度負荷計測を実行します。負荷計測を1時間程度実行したあとのグラフです。




送信側の並列数が増えるにつれてCarbon Metrics Receivedが300万程度まで増えていっています。先ほどとは違いCarbon Committed Pointsも300万程度まで増えており、受信したメトリックをしっかりディスクにフラッシュできているようです。
CPUはiowaitの割合が少し目立ってきました。ディスクは2000〜3000IOPSを推移しています。
Graphiteの書き込みパフォーマンスは特に問題ありませんが、せっかく4vcpusのVMを利用しているので、vcpuの数分carbon-cacheのインスタンス起動してcarbon-relayでバランシングする構成に変更したときにどのような傾向になるかも見てみます。
/etc/carbon/carbon.conf
[cache:b] LINE_RECEIVER_PORT = 2103 PICKLE_RECEIVER_PORT = 2104 CACHE_QUERY_PORT = 7102 [cache:c] LINE_RECEIVER_PORT = 2203 PICKLE_RECEIVER_PORT = 2204 CACHE_QUERY_PORT = 7202 [cache:d] LINE_RECEIVER_PORT = 2303 PICKLE_RECEIVER_PORT = 2304 CACHE_QUERY_PORT = 7302 [relay] RELAY_METHOD = consistent-hashing DESTINATIONS = 127.0.0.1:2004:a, 127.0.0.1:2104:b, 127.0.0.1:2204:c, 127.0.0.1:2304:d
/lib/systemd/system/carbon-cache@.service
[Unit] Description=Graphite Carbon Cache %i After=network.target Documentation=https://graphite.readthedocs.io [Service] Type=forking StandardOutput=syslog StandardError=syslog ExecStart=/usr/bin/carbon-cache --config=/etc/carbon/carbon.conf --instance %i --pidfile=/var/run/carbon-cache-%i.pid --logdir=/var/log/carbon/ start PIDFile=/var/run/carbon-cache-%i.pid [Install] WantedBy=multi-user.target
carbon-cacheを停止して、carbon-cache@a 〜 carbon-cache@dとcarbon-relay@aを起動する。
$ sudo systemctl stop carbon-cache $ sudo systemctl start carbon-cache@a $ sudo systemctl start carbon-cache@b $ sudo systemctl start carbon-cache@c $ sudo systemctl start carbon-cache@d $ sudo systemctl start carbon-relay@a
負荷計測 - 3回目
メトリックの送信先をcarbon-relay(2013ポートで待受け)にします。
$ haggar -agents=300 -metrics=2000 -carbon=localhost:2013
carbon-cacheのグラフは各インスタンスの値が個別の線で表示されていますが、各インスタンスの値の合計がわかりやすいようにグラフを積み上げにしています。

負荷計測を1時間程度実行したあとのグラフです。




Carbon Metrics ReceivedとCarbon Committed Pointsは先ほどと同じで300万程度まで増えています。
CPUはidle以外の合計が400%近くまで増えましたが、その半分をiowaitが占めています。ディスクは5000IOPSが続いており、I/O性能を上限まで使い切れています。さきほどよりIOPSが増えている理由は特に調べていませんが、carbon-cacheのインスタンスを4つにしたことで、今まで1つのプロセスで書き込みをしていたのが4つのプロセスで書き込みするようになったため、書き込みのマージが効きづらくなったのかもしれません。
まとめ
少し前に業務でGraphiteサーバの負荷テストをやりまして、そのときはモニタリングは独自基盤を利用していたのですが、Mackerelでもできそうということでやってみました。
エージェント・メトリックプラグイン・ダッシュボードがいい感じに連携していて、本当に少しの作業でグラフが作れてとても便利ですね。